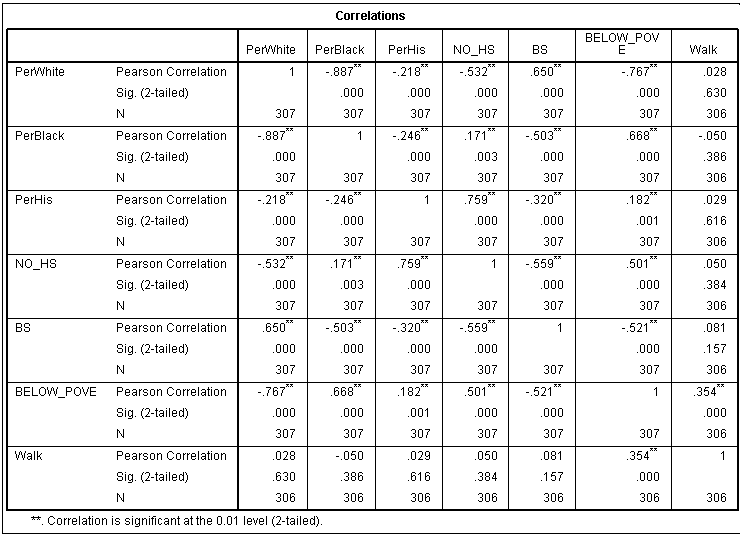
A study done on an unknown town is trying to test to the relationship between the amount of students who get free and reduced lunch and crime rates. A news station within this town has made the claim that as the amount of kids who are receiving free lunch goes up, so does the crime rate. Using the same 44 observations as the news station, a regression analyses will be ran to test if the percentage of persons enrolled in free lunch programs correlates too a differentiation in crime rates. The null hypotheses in this instance would be that there is no relationship between percent of students receiving free lunch and the crime rate within Town X.
Using SPSS to run the regression analyses, the charts in figure 1 were produced. The chart on the bottom, titled coefficients, eludes that there is some degree of linear association between the two variables based off of the significant value of .005, which falls outside of the confidence interval of .05. Also, the B value is 1.685 which indicates that the linear relationship is positive. Subsequently, the top chart, titled Model Summary, provides the R square value which describes the strength of causation between percent students receiving free lunch and crime rates. This value provides what is known as the coefficient of determination, and in this case the value is .173. In conclusion, we acknowledge that there is weak linear association, and therefor we reject the null hypotheses
 |
| Figure 1: charts displaying results of linear regression analyses ran in SPSS. |
Using linear regression equation, what percentage of persons will get free lunch with a crime rate or 79.7?
y = a + bx
independent variable = percent free lunch
dependent variable = crime rate
a= constant (shown in coefficients chart)
b= regression coefficient
y= 79.7%
x=?
79.7= 21.819 + 1.685 (x)
x= 34.35%
Part 2: Introduction
Using the college enrollment data from all 72 counties in the state of Wisconsin, the University of Wisconsin state school system wants know why students chose the schools that they ultimately end up attending. Does the overall trend show students going to schools close by? faraway? Or does the county distance from a school not matter and socio-economic factors like education and household income have more of an effect. It must be acknowledged that there are many unknown variables which can not be accounted for in this analyses, the goal is simply to see if particular variables will display any correlating trends. The data that we have for each county is: % population with a Bachelors degree, median house hold income, and the distance from each county's center to the different UW schools. The schools being used to test the null hypotheses, that there is no linear relationship between distance, % population with a bachelors degree, median house hold income, and the number of people attended, are UW Eau Claire or UW Parkside.
Methods
To find out if any of these factors are significant, a series of regression analyses were conducted to test the relationship between the number of graduates from each school per county and the factors alluded too in the intro. A total of six linear regressions were ran, all of which had either UWEC students or UWPS graduates per county as the the constant dependent variable and pop/distance, median household income, or percent population with a Bachelors Degree as the independent variable. Conducting linear regression indicated if any and what variables affect the amount of students from each county attend the schools in question.
Of these six regression analyses ran, only three were found to be significant based on a one tale test with a 95% confidence interval. So the only results that will be discussed from here forth will be those that fell outside of the 95% range, since they rejected the null hypotheses.
The linear regression that yielded significant results were:
1. population of UWEC students per county compared too population/distance
2. population of UWEC students per county compared too percent population of county with BS degree
3. population of UWPS students per county compared too population/distance
Note: population of students per school in each school was normalized by distance so the counties with large populations don't create false data. The counties that contain the states larger cities cities likely have the most students enrolled all over the state school system, hence why the normalization of distance is necessary.
Results
1. Results of Regression analyses between population UWEC students to population/distance per County.


2. Resaults of regression analyses between population UWEC students and Percent of counties population with a BS Degree.


When analyzing the relationship between UWEC students and percent BS degrees per county county is that there is not a very strong coefficient of determination. Despite the fact that there is a linear relationship between the two variables, the low coefficient determination would indicate that the presence of higher or lower % BS degrees per county has little affect on the amount of students from that county that attend UWEC. Another way this variable could be applied to show stronger relationship is to apply the same variable to the entire network of Wisconsin state schools. This would test the assumption that a college education for ones children is more common if they come from a family or environment where a college education is more common.
3. Results of regression analyses between population of UWPS students percounty and population/distance per county


Similar to the comparison between UW Eau Claire and distance, the comparison between UW Parkside students and population/distance per county also showed a high coefficient of determination. The predictive value of the relationship is especially significant when one looks at the map and can clearly see that not many people attend UWPS who are not from the eastern or south eastern part of the state. Another observation that can clearly be seen is that the highest residual degree is only associated with two counties; the county the school is in (Kenosha) and the county directly north of Kenosha County (Recine). Of all the results discussed, the findings in this analyses show the highest degree of predictive value.
Conclusion
running regression analyses to see what factors contributed to how many people per county go to a certain school yielded some interesting results. The main finding was that the distance between UWEC/UWPS and a given county is a huge factor in predicting where a student will go to university. Personally, i can say that this factor did way into my decision greatly, I dint want to leave too far from home, but i wanted to be far enough away where i want tempted to go home all the time. With that being said, I'm sure many students weigh many other variables when deciding what school to attend, and some universities tend to attract more people from closer locations than others. In light of my results, smaller schools, like UW Park-side, and to a smaller degree, UWEC, would be able to use the results of this analyses to sharpen the focus of their advertising and recruitment to the counties that immediately surround them.

























{kind=link}
{kind=link}