For the introductory portion of this lab, students ran correlation analyses on a data set to test the relationship between distance (ft) and sound level (db). The null hypotheses in this case would be that here is no linear relationship between the distance from the source, and how strong the sound is To test the null hypotheses, the data was analyzed in excel and SPSS to get both the direction and strength of the relationship. The data was used in Excel to create a scatter plot with a trend line, which was used to provide the direction of the correlation. The minimum values of the x an y values were adjusted so the data better filled out the graph area. As the graph indicates, there is a negative correlation where as distance increases, the sound level decreases (figure 1). The next operation was too find the strength of association between these two variables, which was done using the 'bi-variate correlation' tool in SPSS. The resulting r value of -.896 in this operation indicates that there is a strong association between distance and sound level. As a result, we reject the Null hypotheses that there is no linear correlation.
 |
| figure 1 |
 |
| figure 2 |
Part 2: Creating and Analyzing a Correlation Matrix.
Looking at the correlation matrix for the 307 census tracks in Milwaukee County, one can see a range of correlations pertaining to the racial demographics, education, and socio-economic factors within the county. The trend that is displayed in these correlations paints a general picture of segregation and inequality. To exemplify this overall trend within the county, it is important to pay attention to the observable correlation between the variables presented in figure 3 below. The first correlation that shows a degree of segregation is shown in the strong-negative correlation between percent black people/census track and percent white people/census track (-.887). Subsequently, there is a strong positive correlation between percent black people/census track and percent below poverty level/ track (.668). When looking at the same comparison for white people though, you see the opposite trend of a strong negative correlation correlation (-.767). These three correlations previously commented on indicate that on track to track basis, that if there is a high percent of white people in the track, there is a high probability of there being a low percentage of black people and a low percentage of people below the poverty line.
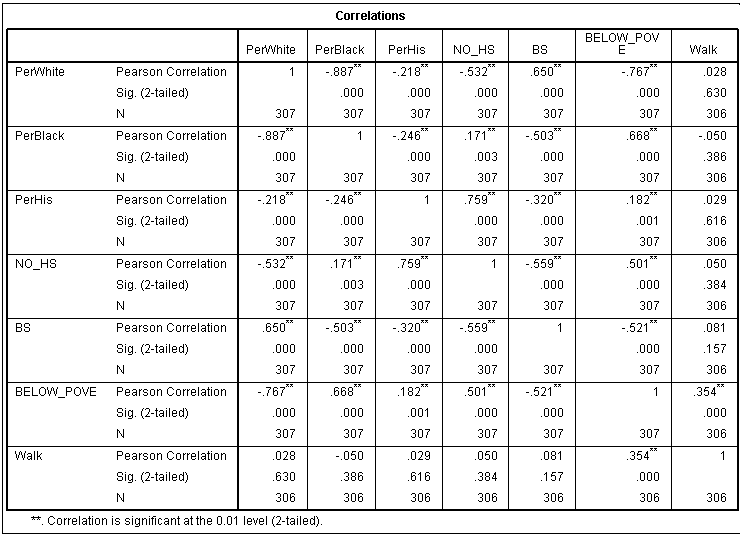 |
| figure 3 |
Part 3: Spatial Autocorrelation - Introduction
For this section, the TEC is asking to find any patterns in voting demographics for elections that occurred in 1980 within the state of Texas. The data you have been given for these two election periods is the overall voter turnout and the percent of the democratic vote, per county. subsequent to this electoral data, data was also downloaded that contained the total population of Hispanics per Texas County in 2010. The goal is to report back if voting patterns have changed in the past 20 years; and if so, how? The null hypotheses that we are testing is if there is no change in voting patterns between 1980 and 2008, and the alternative hypotheses being that there is a difference between in voting trends between these two years.
Methods
Spatial Auto correlation is a tool that is used if one is trying to see how a single variable changes over a given area if the data is in a continuous format. Following Tobler's first law of geography, that things closer together are more related and interconnected than things further away, spatial auto correlation than allows one to create a much more useful concise statistical picture of how a variable undergoes variation over a given space. Most other statistical methods are based on the assumption that the values of observations in each observation, occur independent of one another. Spatial autocorreltaion allows you to see what areas show clusters where there are significantly high values of your variable, clusters of significantly low, and areas where there are hi values surrounded by low, or low values surrounded by hi.
The value used to measure of the degree of autocorrelation in this study is Moran's I. Moran's I is applied to the zones or point where the autocorrelation is being conducted, and provides you with a number between -1 to 1. The closer Moran's I is to 1, the more clustered the the the data is. The direction (+/-) tells you if there is clustering (+) or if there isn't (-).
To visually comprehend how the spatial distribution of Hispanic populations and democratic voters, LISA auto-correlation maps were created to show areas of Texas where clustering is occurring, where it is not, and where out-lier counties are. In order to create these maps, a spatial weight must be created within Opengeoda. The spatial weight that was created was based off of shared border length. as a result, Larger counties which had more a large boarder perimeter, and a large amount of smaller counties around it were given a heavier weight than smaller counties. This addition of a spatial weight to the auto correlation provides a spatial element that helps create areas of clustered similarities.
To produce these values and maps, all data and weights were created/inputted into in OpenGeoda, a free interface for geo-statistical analyses. the correlation matrix produced was created in SPSS.
Results and Subsequent Conclusions

- High - High = counties that show a high level of the variable, and are surrounded by other counties which exhibit high levels of the variable
- Low-Low = counties that show a low level of the variable and are surrounded by other counties which exhibit low levels of the variable
- Low - High = counties that exhibit a low level of the variable but are near areas that show a high level of the variable
- High - Low = counties that show high levels of variables but are near areas that show low levels of the variable
Percent of population of Hispanics per County in Texas, 2010
 |

{kind=link}
This map illustrates the highest degree of spatial autocorrelation out of all the observations. Along the border with mexico, there is distinctly visible high-high clustering, and a high degree of low-low clustering in the Eastern part of the state. besides a select few high-low or low-high outliers, The general trend suggests that Hispanic populations are more concentrated near the Mexican border in the south/south western part of the state, and moves toward low-low levels of clustering as you move north and east. In addition to the visual prevalence of the clustering, the subsequent Moran's I of .78 further suggest a high degree of positive autocorrelation.
Percent Democratic voter turnout (2008 top - 1980 bottom)


{kind=link}


Between the years of 1980 and 2008, the voting pattern of percent democratic voters become more clustered and less random. where there was once counties of 'high-high' democratic vote percentage in 1980, there isn't in in 2008. The maps would suggest that for some reason the democratic vote shifted from pockets in the south/south east to being more concentrated near the border areas in the south/south west, and a small part of the north east. Subsequently, the Moran's I value increased between these two years from 0.58 to .7, further indicating that a higher degree of clustering is occurring of percent democratic vote turnout per for each county in Texas.
Voter turnout (2008 top - 1980 bottom)



Unlike the spatial auto correlation conducted on percent democratic vote between the two years 1980 and 2008, the spatial auto correlation of overall voter turnout between 1980 and 2008 showed a decrease in the amount of clustering; the Moran's I score drooped from .46 in 1980 to .36 in 2008. The clustering that is still occurring, however, has shifted from the south west of the state up toward the middle, north and north eastern parts of the state. Subsequently the, southern tip of the state that was almost entirely high-high, is now entirely low-low. The reason for this switch could be any number of factors; growth of population in new areas, the decrease of population in other areas.
To further investigate if there are any correlations between the variables that occurred in the same year (2008), a correlation matrix was produced in SPSS. Since it would make no sense to analyze the correlation of things that occurred 28 years apart, the correlation focused on the comparing percent Hispanic population per county, and the 2008 % democratic vote and overall voter turn out per county. what can be seen is a moderately strong negative correlation between % Hispanic population and voter turnout but see a moderate strong correlation between % Hispanic population and % democratic turnout. The later observation indicates that as the % of democratic voters increases through out the state, there is a significant probability that you will find a higher % of a counties population being Hispanic. Transversely, the moderately strong negative correlation between % Hispanic population and overall voter turnout suggests a higher probability of counties that have a low voter turnout also having a high percentage of the population being Hispanic.

Report to the TEC
In conclusion to the reports and maps created, the Null hypotheses would be rejected in this scenario because a large spatial shift in voter turnout and % democratic vote can be observed across counties within the state of Texas between 1980 and 2008. Reporting to the Governor, the findings from this report would suggest that the spatial distribution of voting patterns have changed from 1980 to 2008. The southern part of the state which in 1980 exhibited an area with a predominantly low voter turnout made a complete change to 2008, and became an area of high voter turnout. one possible reasoning for this could be related to the high Hispanic population that we now see there in the 2010 data. With more time and resources, analyzing the Hispanic populations within the state around the time of the 1980 election would allow for a more in depth analyses of the possible influence of Hispanic population on the overall voter turn out within the state of Texas. In terms of the % democratic vote, the shift of clustering toward the southwestern part of the state coincides well with the % Hispanic population clustering exhibited in 2010. At this point in time, Hispanics largely vote democratic, so this trend isn't particularly alarming. The governor now should be better able to comprise a plan of action of where to focus his campaign efforts to reach the parts of the state with the highest voter turnout and while also targeting clusters of Hispanic populations.
No comments:
Post a Comment